 1 month ago
14
1 month ago
14
지난 (1)편에서는 카오스 엔지니어링을 시작하며 겪었던 이슈와 진행 과정을 소개했습니다. 이번 글에서는 카오스 실험을 통해 얻은 인사이트를 정리해보겠습니다.
작성에 앞서 실험 환경에 대해 소개하겠습니다.
24시간 365일 서비스를 운영해야 하는 특성상, 운영 환경에 직접 장애를 주입하는 것은 리스크가 크다고 판단하여 Stage 환경에서 실험을 진행했습니다.
또한 운영 환경과 최대한 유사한 트래픽 패턴을 재현하기 위해 Locust를 사용해 일정한 시나리오 기반 트래픽을 실험 기간 동안 지속적으로 발생시키고, 그 상태에서 장애를 주입하는 방식으로 테스트를 수행했습니다.
Pod Network Latency 주입 시나리오
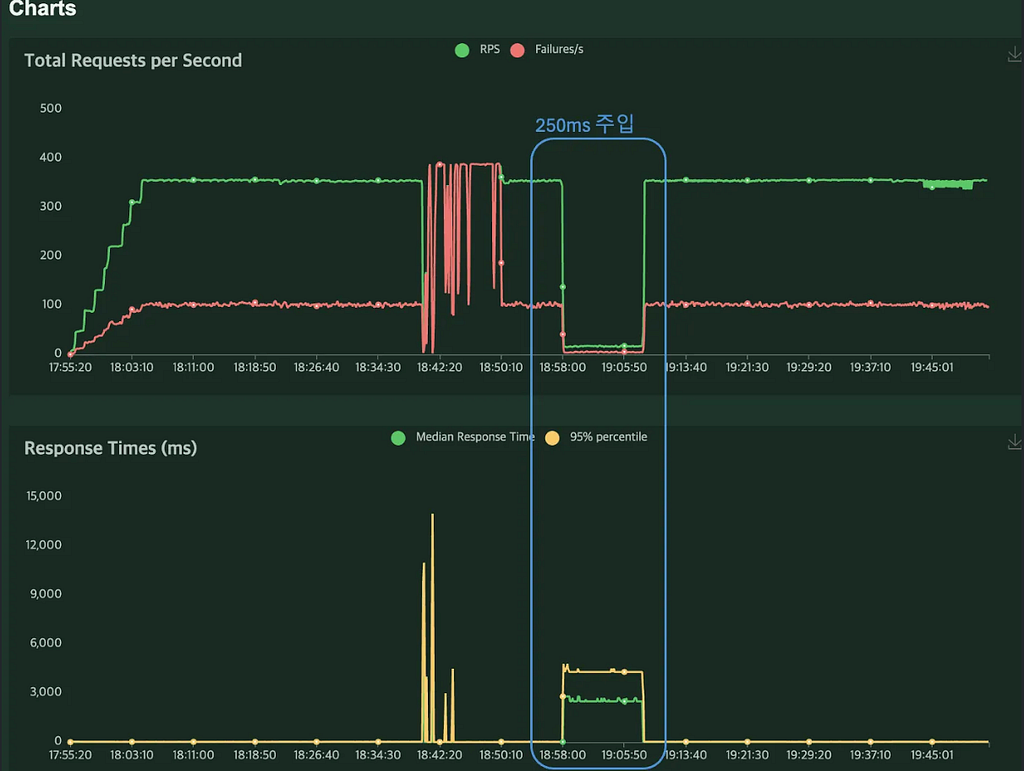
최초 계획은 1차 실험에서 500ms, 2차 실험에서 1000ms의 Pod 네트워크 지연(Latency)을 주입하는 것이었습니다. 그러나 1차 실험 결과를 바탕으로 2차 실험 목표를 250ms로 조정했습니다.
실험 결과는 인프라 지표와 클라이언트(Locust 기반) 지표를 각각 정리한 뒤, 서비스 영향도를 Happy Path Test로 확인하는 방식으로 검증했습니다.
사전 단계에서 “기본이 되는 요청”이 지속적으로 발생하는 상황에서 Pod Network Latency를 주입해야 의미 있는 결과를 얻을 수 있었습니다. 이 부분은 QA 팀의 지원을 받아 테스트 시작 전부터 트래픽을 주입했고, 그 결과 Membershipyo 서비스에 약 350 RPS 수준의 요청을 생성할 수 있었습니다.
A. Pod Latency 실험 (500 ms)
- 수행시간 : 18:40 ~ 18:50
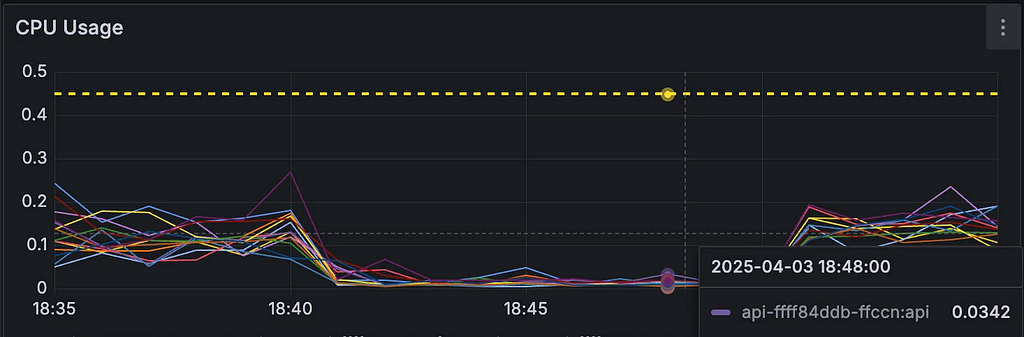
- Pod CPU 사용량
실험 전에는 Pod CPU 사용량이 0.1 ~ 0.2 core 수준이었으나, 장애 주입 중에는 0.01 ~ 0.03 core로 크게 감소했습니다. 이는 Pod가 정상적인 처리(컴퓨팅)를 거의 수행하지 못한 상태로 해석할 수 있습니다.
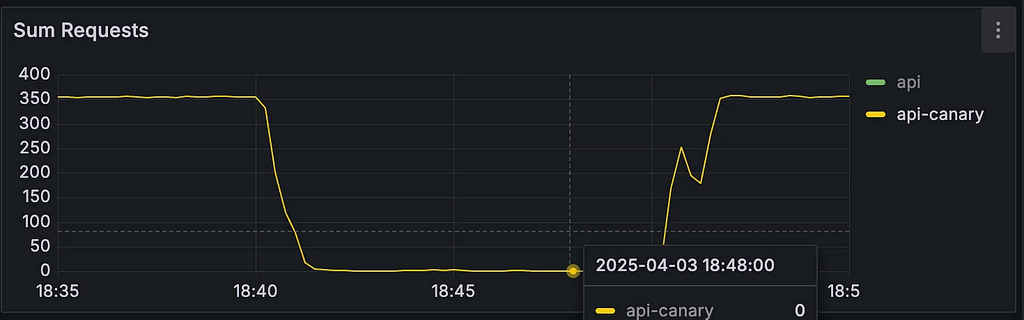
- 요청 RPS (Request Per Second)
실험 전 Membershipyo 서비스의 RPS는 약 350이었으나, 장애 주입 후에는 거의 0에 수렴하며 요청이 들어오지 못하는 것으로 보였습니다. 단순히 Latency가 증가한 것만으로 이 정도까지 처리량이 떨어지는 것은 비정상적으로 보여, 추가 원인이 있을 것으로 예상했습니다.
- 요청 Duration 시간 (P99)
평소 25ms 이하로 처리되던 요청이 장애 주입 후 최대 30초까지 증가했습니다. 이 수준에서는 사실상 정상적인 서비스 제공이 어렵다고 판단할 수 있습니다.

(참고) Locust 환경 설정
vuser : 40 , Base RPS : 350
Locust는 기본적으로 응답 속도에 따라 RPS를 조정합니다.
“40 / 응답속도(초) ≈ 350 RPS”이므로 평균 응답속도는 약 0.11초 수준으로 추정할 수 있습니다.
- Locust 메트릭
500ms Pod Latency 주입 시, RPS가 크게 요동치며 대부분 요청이 Failure로 처리되는 것을 확인했습니다. 특히 RPS와 Failure 지표가 함께 크게 출렁이는 현상이 특징적이었습니다.
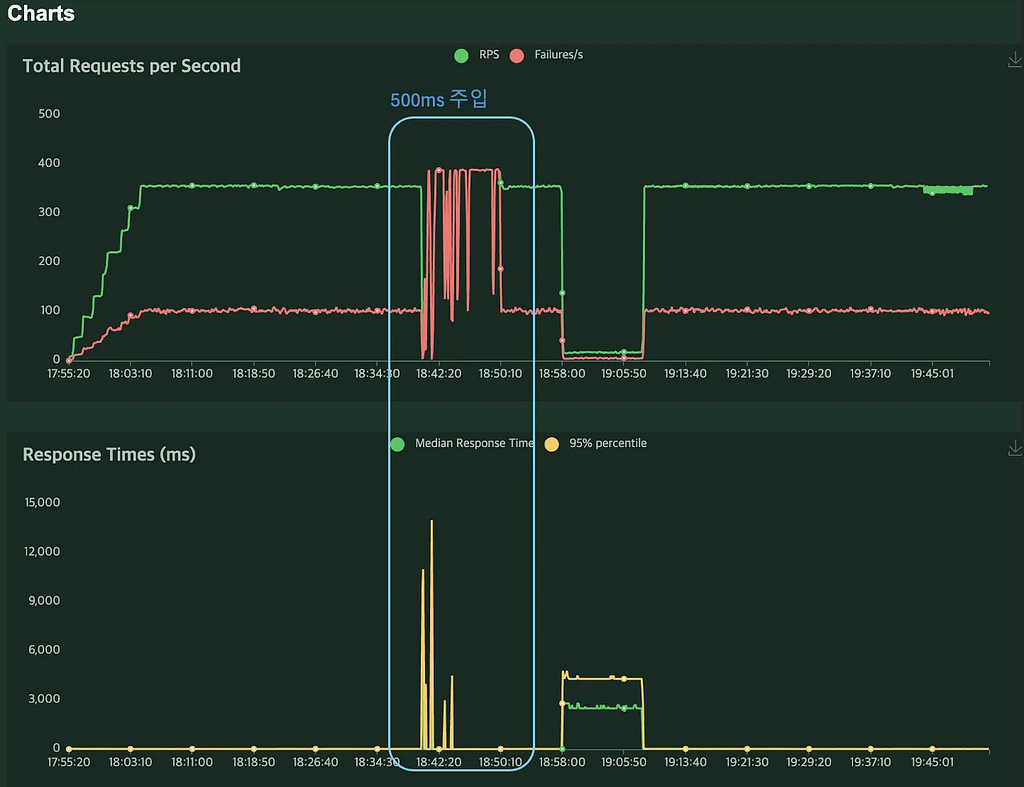
Locust는 응답을 받으면 해당 응답 시간을 기준으로 RPS를 조정합니다. 그런데 RPS가 이 정도로 요동친다는 점은 일반적인 “지연 증가”만으로는 설명이 어려워, 뒤에서 추가 분석을 통해 원인을 더 살펴보겠습니다.
3. App 모니터링- App Log 확인
Datadog에서 확인되는 애플리케이션 로그 수는 많지 않았지만, 확인된 로그는 HTTP 500 응답 에러가 Uncaught Error로 처리되는 형태였습니다.

- Trace Log 확인
Trace를 따라가며 Redisson 관련 에러를 확인했습니다.
Unable to write command into connection!Check CPU usage of the JVM.
Try to increase nettyThreads setting.
메시지 내용으로 보아 애플리케이션에서 Redis 연결 과정에서 사용할 Netty 스레드/커넥션 리소스가 소진된 상태로 해석할 수 있었습니다.
500ms Pod Latency를 주입했을 때, Pod가 Redis에 연결하는 단계에서 스레드가 대기(Queue)를 점유하면서, 새로운 요청이 사용할 스레드가 부족해지는 현상이 발생했습니다. 이로 인해 Pod 상태가 악화되고, 높은 Failure로 이어진 것으로 판단했습니다.
4. 사용자 경험- 비 구독자 주문
비구독자는 기능 반응이 지연되는 것을 체감했으나, 기능 자체는 정상 동작하는 것을 확인했습니다.
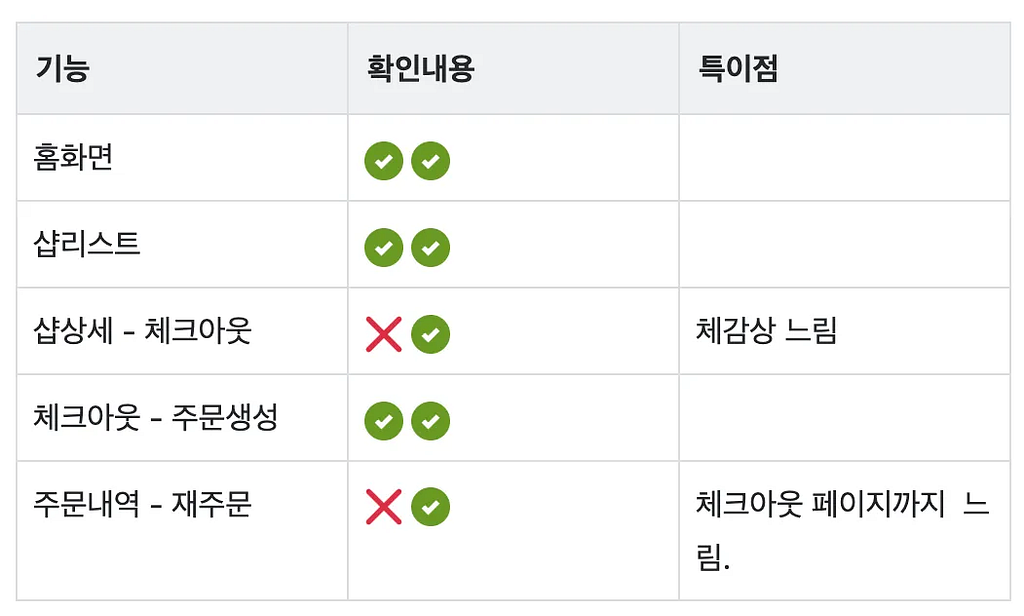
- 구독자 주문
구독자는 체크아웃 페이지로 진입이 불가능해 실제로 앱에서 주문이 불가능한 경험을 하게 됐습니다.
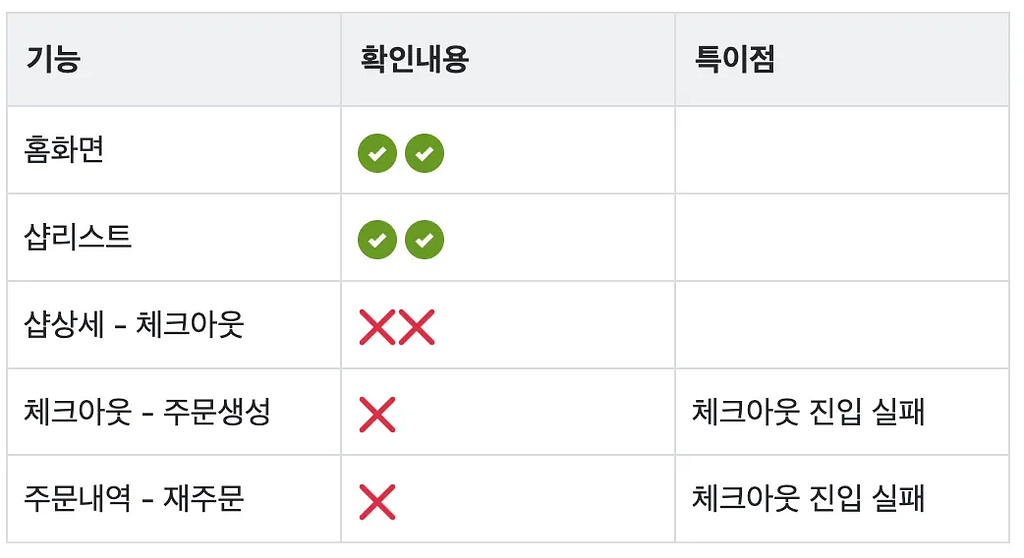
이는 주문 단계에서 “멤버십 여부 확인”이 실패하면 더 이상 진행이 불가능한 구조로 보였고, 개선이 필요하다고 판단하여 유관 부서에 내용을 공유했습니다.
5. 추가 분석 (istio)500ms Latency 주입 시 클라이언트 측 RPS가 요동친 현상과, 동시에 App 로그가 적게 남은 이유를 확인하기 위해 추가 분석을 진행했습니다.
- 트래픽 Flow
트래픽 흐름을 살펴보면 다음과 같습니다.
Locust → ALB → Istio IngressGateway → 서비스 Pod
- Istio ingress gateway log 확인 (UH Response_flag를 가진 Log)
UH 플래그는 Unhealthy Upstream Host를 의미하며, 전달할 “건강한 업스트림 Pod가 없다”는 뜻입니다. 즉, Redis 연결 문제가 발생한 Pod가 정상적인 상태를 유지하지 못하면서, Istio Gateway가 해당 Pod를 라우팅 대상에서 제외했음을 의미합니다.
 실험 시간 동안 대량의 UH flag를 지닌 Packet이 istio ingress gw로 부터 즉시 응답되었습니다.
실험 시간 동안 대량의 UH flag를 지닌 Packet이 istio ingress gw로 부터 즉시 응답되었습니다.- Log Sample
위에서 발생한 Log를 살펴보면 다음과 같은 HTTP 503 응답을 대량으로 발생시켰다는 것을 확인했습니다.
{"method": "GET",
"user_agent": "iOS/iPhone Simulator/12.0.0/yogiyo-ios-***",
"upstream_transport_failure_reason": null,
"response_code": 503,
"upstream_service_time": null,
"x_forwarded_for": "*.*.*.*,*.*.*.*",
"response_flags": "UH",
"response_code_details": "no_healthy_upstream",
. . .
"downstream_local_address": "*.*.*.*:**",
"route_name": "default",
"protocol": "HTTP/1.1",
"authority": "membershipyo.****",
"duration": 0,
"start_time": "2025-04-03T09:49:59.963Z",
"connection_termination_details": null,
"bytes_received": 0,
"upstream_local_address": null,
"upstream_host": null
}
Duration = 0 을 통해서 즉시 응답한 것을 알 수 있습니다.
- Istio를 통과한 Log 개수 수집
100% 실패한 것은 아니며, 소수의 성공 패킷도 있었던 것으로 보입니다. 다만 이 성공 패킷은 매우 긴 응답 시간을 가진 것이 특징이었습니다.
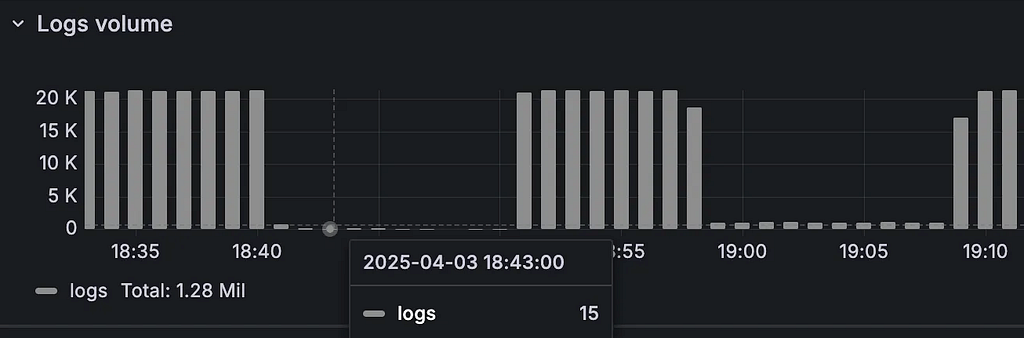
- Client 지표에서 RPS가 요동친 이유
- Pod의 Health Check가 실패하면서 트래픽을 처리할 Pod가 없었습니다.
2. Istio Proxy가 UH 플래그 응답을 매우 빠르게 반환하면서, Locust 입장에서는 낮은 응답속도를 반영하여 RPS를 일시적으로 높게 설정했습니다. (실제 서비스 로직 처리가 없었기 때문에 오히려 350 RPS를 초과하기도 했습니다)
3. 간헐적으로 Istio를 통과한 패킷은 응답 시간이 매우 길었고, Locust는 이를 다시 반영해 요청 RPS를 급격히 낮췄습니다.
4. 결과적으로 “빠른 실패 응답(즉시 반환)”과 “매우 느린 성공 응답”이 번갈아 발생하면서, 클라이언트 지표에서 RPS가 크게 요동친 것으로 해석할 수 있습니다.
5. 대부분의 요청이 Istio에서 차단 및 즉시 응답이 반환되어 App의 로그가 적게 남았던 점도 이 흐름과 일치합니다.
B. Latency 주입 실험 (250 ms)
수행시간 : 18:57 ~ 19:08
1 . 인프라 모니터링- Pod CPU 사용량
실험 전 0.1 ~ 0.2 core 수준이던 CPU 사용량이 장애 주입 후 0.02 ~ 0.03 core로 감소했습니다. 500ms에 비해서는 상대적으로 높은 CPU 사용량을 유지했습니다.

- 요청 RPS 수 (Request Per Second)
장애 주입 전 RPS는 약 350이었으나, 주입 후에는 약 17 RPS로 감소해 실험 시간 동안 비교적 일정하게 유지되었습니다. 앞선 500ms 실험에서 거의 0에 가깝게 떨어졌던 결과에 비하면 낮지만 “지속 가능한 수준”으로 유지된 점이 특징입니다.

- 요청 Duration 시간 (P99)
평소 25ms 이하로 처리되던 요청이 장애 주입 후 약 5초로 증가했습니다. 이는 약 20배 증가이며, 위에서 관찰한 RPS가 약 20배 감소한 것과 반비례 관계로 나타났습니다.

- Locust 메트릭
250ms Pod Latency 주입 시에는 RPS가 약 15 수준으로 안정화됐고, Failure가 거의 사라졌습니다.
응답 시간 중앙값이 약 2.7초였기 때문에, “40 / 2.7 ≈ 15 RPS”로 설명할 수 있습니다
App 모니터링에서 특이 사항은 없었습니다. 에러 로그도 발견되지 않았고, 사용자 경험에도 문제가 없었습니다.
즉 250ms Pod Latency로 인해 응답 속도는 느려졌지만, Pod 상태는 정상으로 유지됐고 Redis 연결도 안정적이었기 때문에 Happy Path Test도 정상 통과했다고 볼 수 있습니다.
C. Pod Network Latency 실험 후 얻은 인사이트
해당 실험을 통해서 얻은 인사이트를 5가지 정리해보면 다음과 같습니다.
- Redisson Error 예외처리 추가
Redisson Error 발생 시 예외 처리를 하지 않아서 Unknown Error로 정확한 원인을 직관적으로 알아보기 어려웠는데, 해당 에러 케이스를 추가하여 에러를 직관적으로 볼 수 있는 개선안을 찾을 수 있었습니다. - 구독 회원의 주문 실패 확인
멤버십 서비스가 다운되었을 때, 구독 회원이 주문페이지에 랜딩하지 못하는 상황을 확인했습니다. 멤버십 서비스가 정상적으로 응답하지 못할 때 비 동기적으로 처리하여, 서비스를 지속적으로 사용할 수 있는 방안으로 개선 포인트를 찾을 수 있었습니다. - 멤버십요의 Bottleneck 확인
EKS Pod의 헬스체크가 실패한 이유는 Redis의 Queue를 점유한 부분에서 발생하였는데, 해당 부분을 조금 더 확장하거나 능동적으로 Queue관리할 수 있는 로직을 추가함으로서 Queue가 부족하지 않도록 조정할 수 있는 개선 포인트를 찾을 수 있었습니다. - Pod Network Latency 영향도 확인
운영환경과 유사한 상황을 만들기 위해 Base Request를 Locust로 발생시켰습니다. 단순 Health Check가 아닌 시나리오를 기반해서 요청이 동작하기에 여러 연동 서비스를 거치게 되는데, Pod에 적용된 Latency는 매 요청마다 대기가 되기에 생각보다 영향이 컸습니다. - AWS FIS 서비스 경험 및 제약조건 이해
이번에 장애 주입 도구인 AWS FIS를 사용하면서 어떤 기능을 제공하는지 경험할 수 있었고, 제약조건도 이해할 수 있었습니다. AWS Console에서 간편하게 수행하거나 Stop Condition을 설정할수도 있다는 것은 큰 장점이였고, 권한 부여가 조직의 거버넌스와 맞물리게 되면 까다로울 수 있다는 점을 느꼈습니다. AWS FIS는 지속적으로 기능이 업데이트 되고 있는 것으로 보여 이후에는 또 다른 기능도 사용해보면 괜찮을 것 같습니다.
외부 API 통신장애 주입
수행 시간: 19:10 ~ 19:30
외부 협력업체를 통해 가입한 멤버십의 경우, 탈퇴 시 외부 API를 호출해 탈퇴 처리합니다. 이 외부 API 통신에 장애를 주입했을 때 DB 정합성 및 다른 기능에 영향이 있는지 확인하는 테스트를 진행했습니다.
A. 외부 API 차단
- 장애 주입
외부 API에 대한 IP를 outbound 차단 정책을 이용해서 차단 하였습니다. 다행이 단일 IP만 차단하면 막히는 것으로 확인되어 간단하게 AWS NACL을 통해 쉽게 장애를 주입할 수 있었습니다.

- 탈퇴 API 상태 확인
연계된 회원 탈퇴를 위해서는 외부 협력사에서 제공하는 wiithdraw-subscription API를 호출해서 탈퇴를 진행합니다.
Outbound IP를 차단 후, wiithdraw-subscription API에 에러율이 급증하는 것을 확인하여 의도한 대로 차단이 되었음을 확인했습니다.

APM Dependency Map에서 100% 실패하는 것을 확인했습니다.
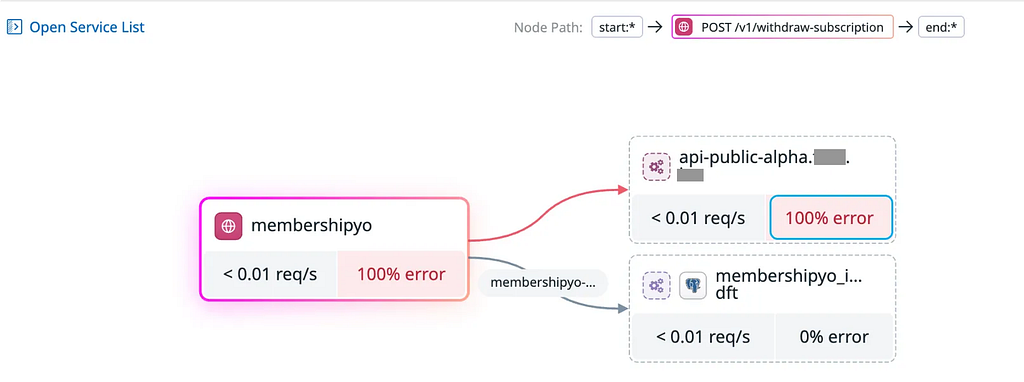
- HTTP Response Code 500 으로 응답되는 것을 확인했습니다.

- 구독 관련 Data 정합성 확인
DB의 멤버 정보에서 Started_at (구독 시작일) Finished_at (구독 종료일) 등에 문제가 없는지 정합성에 대한 확인을 하였고 이상 없다는 것을 확인 했습니다.
3 . 사용자 경험Happy Path Test를 통해서 의도한 구독 해지 실패 기능 외에는 모두 정상 동작 했음을 확인 했습니다.
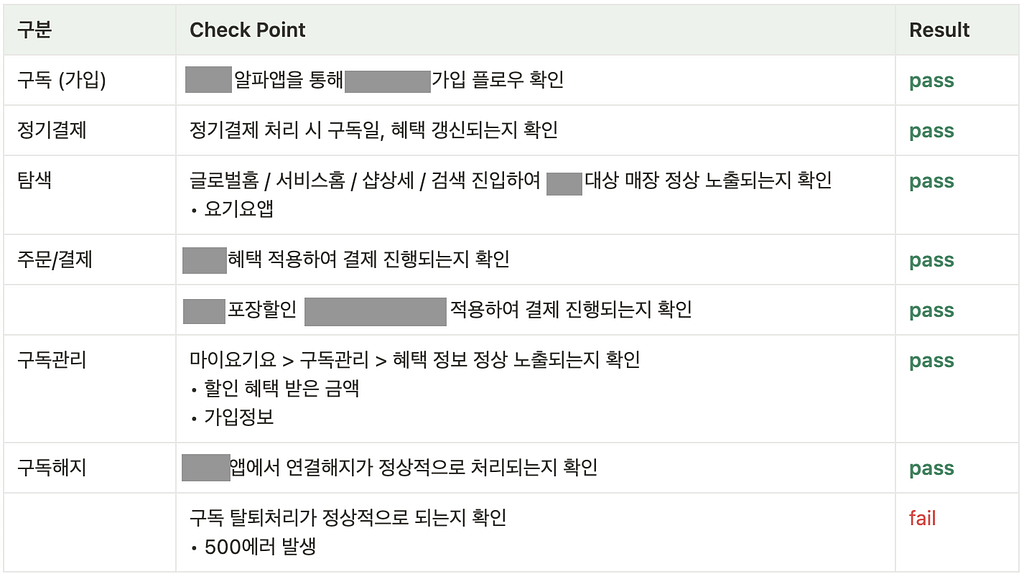
B. 외부 API 통신 장애 결론 공유
외부 API 호출 장애가 발생하더라도, 회원 탈퇴를 제외한 다른 멤버십 관련 기능이 정상 동작함을 확인했습니다. 즉, 해당 기능 범위에서는 외부 벤더 장애에 대해 일정 수준의 내성이 있음을 확인할 수 있었습니다.
이번 카오스 엔지니어링 실험을 마치며 . . .
이번 실험에서 가장 어려웠던 부분은 시나리오를 구체화하는 과정과, 실험 단계에서 관찰해야 할 핵심 지표를 도출하는 과정이었습니다. 처음 카오스 엔지니어링을 기획할 때는 막연한 부분이 많았고, 장애 주입 도구 및 부하 테스트 도구에 대한 기술적 이해가 필요했습니다. 또한 우리 서비스 환경에 맞게 설정을 조정해야 했기 때문에 사전 학습과 테스트도 병행해야 했습니다.
그럼에도 여러 구성원과 논의하며 시나리오와 실험 방법을 점진적으로 구체화할 수 있었고, 실험 결과를 분석·정리하는 과정에서 예상하지 못했던 개선 포인트도 발견할 수 있었습니다. 또한 일부는 예상대로 잘 동작하는 부분을 확인할 수 있었던 점도 의미가 있었습니다.
개인적으로는 여러 부서와 협업하는 과정에서 각 팀의 업무에 대해서 더 잘 이해할 수 있었던 부분도 특히 좋았습니다.
이번에는 “멤버십”이라는 특정 서비스를 대상으로 진행했지만, 여러 마이크로서비스로 확장해 실험한다면 더 많은 인사이트를 얻을 수 있을 것으로 기대합니다. 함께 고생해주신 여러 조직원들께 감사의 마음을 전하며 글을 마치겠습니다.
[요기요 카오스 엔지니어링 (2)] 카오스 실험 결과 정리하기 was originally published in YOGIYO Tech Blog - 요기요 기술블로그 on Medium, where people are continuing the conversation by highlighting and responding to this story.








 English (US) ·
English (US) · 