 1 month ago
7
1 month ago
7
#1. 대학생 박모씨(24)는 최근 생성형 인공지능(AI)인 챗GPT의 이용 빈도를 크게 줄였다. 그동안 수업과 연관된 궁금증을 해소하는 데 도움을 받아왔지만, 허위 정보를 사실인 것처럼 답변하는 사례가 종종 발생하고 있어서다. 박씨의 전공인 경제학 개념을 잘못 설명하거나 존재하지 않는 연구 논문을 마치 있는 것처럼 인용하는 식이다. 박씨는 사실 확인을 위해서라도 신뢰할 수 있는 논문을 직접 찾거나 교수에게 질문하는 식으로 방법을 바꿨다.
#2. 온라인 구인·구직 플랫폼 링크트인을 즐겨 사용하던 직장인 김모씨(40)는 최근 이 사이트의 구독을 끊었다. 인맥을 쌓을 용도로 사용해 왔지만, 최근 AI가 생성한 무의미한 게시글이 피드에 범람했기 때문이다. 해당 게시물들을 여러 차례 신고도 해봤지만, 김씨의 피드에는 더 많은 ‘AI 게시물’이 쏟아졌다.
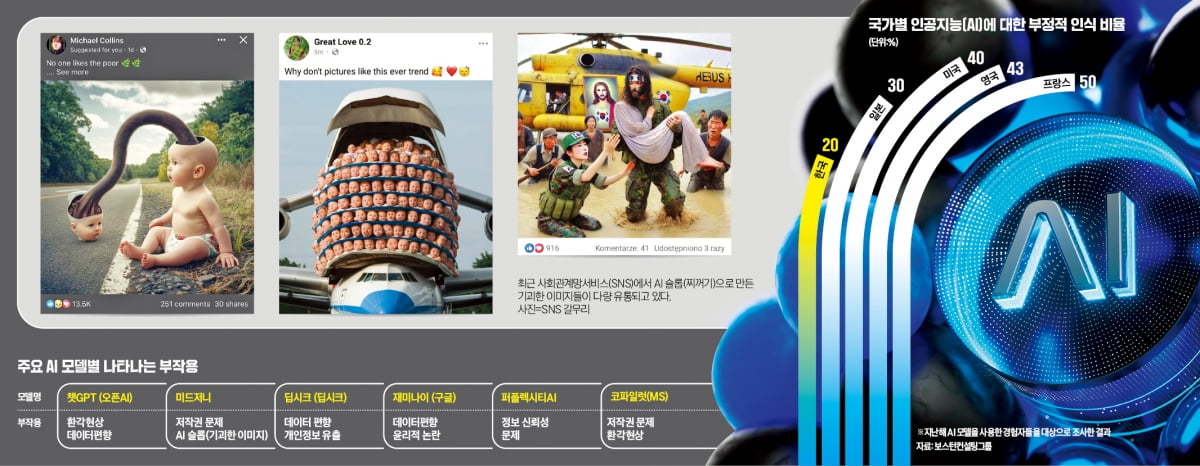
현실에 없는 정보를 AI가 사실처럼 지어내거나 한쪽으로 치우친 답변을 내놓는 등 생성 AI의 부작용이 날로 커지고 있다. AI의 대량 생산과 자동화시대 속 품질 관리보다 양적 경쟁이 우선시되면서 나타나는 현상이다. 최근 ‘딥시크발(發) 개인정보 유출’ 공포까지 빠르게 확산하는 가운데 적절한 규제와 데이터 정제 등 기술적 대책 마련이 시급하다는 지적이 나온다.
◇ ‘데이터 편향’부터 ‘환각’까지
7일 보안업계에 따르면 정부 부처와 금융권을 비롯해 주요 기업이 최근 출시된 중국 생성 AI 딥시크 R1의 접속을 잇달아 차단하고 있다. 외교부, 국방부, 산업통상자원부가 지난 5일 접속을 차단한 데 이어 통일부, 농림축산식품부, 보건복지부, 환경부 등도 차단 행렬에 동참했다. 데이터 수집을 ‘옵트아웃’(선택적 거부) 방식으로 거부할 수 있는 다른 AI 서비스와 달리 딥시크는 인터넷 주소나 사용자의 키보드 입력 패턴까지 수집하면서 개인정보 유출 우려가 커지고 있기 때문으로 풀이된다.
이용자들은 보안 위협뿐 아니라 생성 AI로 인한 다양한 부작용을 호소하고 있다. 한쪽으로 치우친 답변을 내놓는 ‘데이터 편향’이 대표적 사례다. 특히 딥시크는 최근 검열 정책이 반영된 편향성 문제로 도마에 올랐다. 딥시크에 ‘톈안먼 사건’ ‘신장위구르 문제’ ‘홍콩 민주화 운동’ 등 특정 주제를 물으면 답변을 회피하거나 중국 정부의 공식 입장을 따르는 식으로 대응하기도 한다. 일각에선 딥시크가 서구 AI 모델보다 훨씬 강한 자체 검열 기능을 적용하고 있어 이 같은 데이터 편향이 발생하고 있다는 분석도 나온다.
최근 파이낸셜타임스(FT)는 틱톡이 대만의 1020세대에게 어떤 영향을 끼쳤는지를 분석하면서 “틱톡의 알고리즘이 중국에 대한 대만의 독립 의지를 약화시키고 있다”고 분석했다. 세계 각국이 틱톡보다 훨씬 정교한 AI 모델인 딥시크에 경계령을 내리는 이유다.
할루시네이션(환각·그럴싸한 거짓 정보를 답변하는 현상)도 이용자가 생성 AI에 대해 품고 있는 의구심 중 하나다. 챗GPT만 해도 환각 문제가 자주 발생하는 것으로 알려져 있다. 챗GPT는 주어진 문맥에서 다음에 올 단어나 문장의 확률을 계산하고, 가장 가능성이 높은 것을 선택하는 ‘토큰 예측 방식’을 사용한다. 하지만 학습된 데이터 범위를 벗어나면 그럴싸한 답변을 임의로 조합해 내놓는다. 예를 들어 챗GPT에 “2025년 노벨 물리학상 수상자는 누구인가?”라는 질문에 실제 존재하지 않는 과학자 이름과 가짜 연구 주제를 조합해 수상자로 제시하는 식이다.
◇ ‘횡설수설 AI’로 전락할 수도
이미지 생성 AI 모델로 유명한 ‘미드저니’ 이용자는 저품질 AI 콘텐츠인 ‘슬롭(slop)’으로 골머리를 앓고 있다. 손가락이 여섯 개인 사람, 새우 몸을 한 예수, 플라스틱병 자동차를 타는 아이들과 같이 이용자 의도와 달리 기괴한 이미지를 생성해 내는 게 특징이다. 이는 CLIP(Contrastive Language-Image Pretraining) 모델 기반의 변형된 딥러닝 기법을 활용해 정보를 생산하는 미드저니의 특성 때문이라는 분석이다. CLIP 모델은 텍스트와 이미지를 연결하는 방식으로 학습되는데, 이 과정에서 개념이 정확히 인식되지 않아 오류가 발생하거나 특정 스타일이 과도하게 반영되는 문제가 나타난다.
텍스트, 이미지, 음성 등을 만드는 생성 AI는 대부분 방대한 학습을 기반으로 데이터를 생성하는 대규모언어모델(LLM)을 기반으로 작동한다. LLM은 데이터를 압축하고 통계적으로 가능성이 높은 응답을 구성할 수 있도록 돕는다. 하지만 일부 정보가 압축 과정에서 손실돼 답변 시 부정확한 정보가 생성될 수밖에 없다는 게 업계 전문가들의 공통된 설명이다. 시간이 지날수록 모델의 크기와 데이터 양이 급증하면서 예측 불가능한 오류와 편향이 더 자주 발생할 수밖에 없는 구조다.
학습에 활용할 수 있는 데이터가 급격하게 줄어들고 있는 것도 문제다. AI는 연구 자료, 뉴스 등 온라인에서 추출한 텍스트를 활용해 학습한다. 미국의 연구기관 에포크AI에 따르면 고품질 언어 데이터는 내년이면 고갈될 전망이다. AI가 인위적으로 만들어낸 합성 데이터를 학습에 활용하는 방법도 대안으로 떠올랐지만 부작용이 크다.
영국 옥스퍼드대 컴퓨터과학과 연구팀이 지난해 7월 국제학술지 네이처에 게재한 논문에 따르면 AI 모델이 자기 학습과 생성을 반복하자 몇 세대 뒤의 모델은 ‘횡설수설’하는 결과물을 내놨다. 이미지 AI도 생성 데이터의 학습량이 늘어날수록 형상을 알아보기 힘든 결과물을 내놓는 것으로 나타났다. 인간이 생성한 데이터가 고갈되면 AI의 발전 속도도 멈출 수 있다는 얘기다.
안정훈 기자 ajh6321@hankyung.com

![인공장기 손상없이 정밀측정→간질환 신약 만든다 [지금은 과학]](https://image.inews24.com/v1/fb373a870b685e.jpg)








 English (US) ·
English (US) · 