주요 논점
1. 실제 활용 가능한 컨텍스트 크기
2. Gemini 성능
3. GPT-5 평가
4. Claude 평가
5. Qwen, Mistral, Gemma 등
6. Llama 시리즈
7. 모델별 세부 경험
기타
결론
지난 5년간 LLM 컨텍스트 윈도우의 크기 확장 타임라인
 18 hours ago
1
18 hours ago
1
Related

Show GN: SHA 고정 기능을 통해 GitHub Actions를 업데이트하는 대화형 CLI 도구
10 hours ago
2
저희 투자사(!)에서 저희 앱의 JS SDK를 만들어주셨습니다
12 hours ago
1
유령 구직 공고 금지 제안
13 hours ago
1

신용대출 찾기 서비스 제휴사 Mock 서버 개발기 #2
14 hours ago
0

코드 품질 개선 기법 18편: 함수만 보고 관계는 보지 못한다
17 hours ago
1

리디, 글로벌 웹툰 2년 연속 미국 ‘링고 어워드’ 노미네이트
17 hours ago
0
미국 정부의 Intel 지분 인수
17 hours ago
0
Framework Laptop 16
17 hours ago
1
Popular

Boost Your Career with SAP Integration Suite Certification
3 weeks ago
25

What Can AI Do Inside SAP Build? | What Can You Build?
2 weeks ago
24




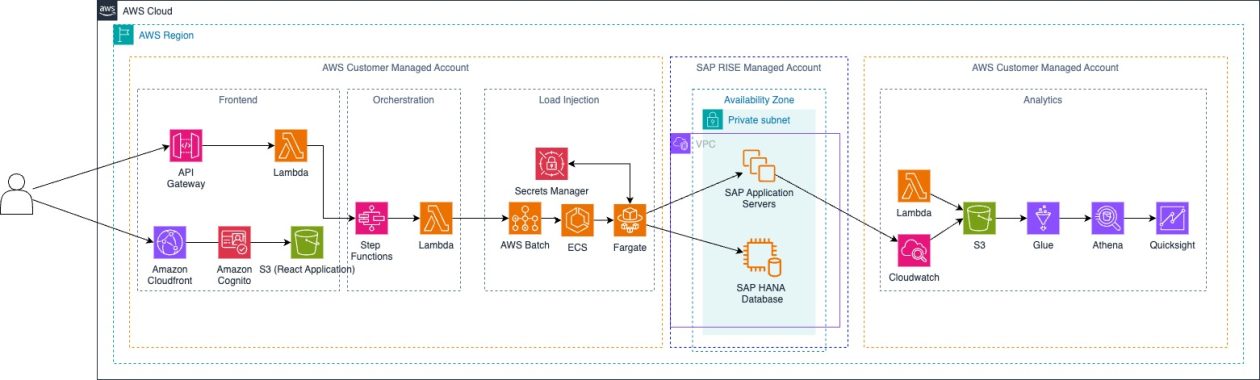
SAP Load Testing: a serverless approach with AWS
2 weeks ago
18

What Is SAP Bank Communication Management?
4 weeks ago
18
PureGym의 비공식 Apple Wallet 개발자가 된 계기
1 week ago
18

 English (US) ·
English (US) · © Clint IT 2025. All rights are reserved
