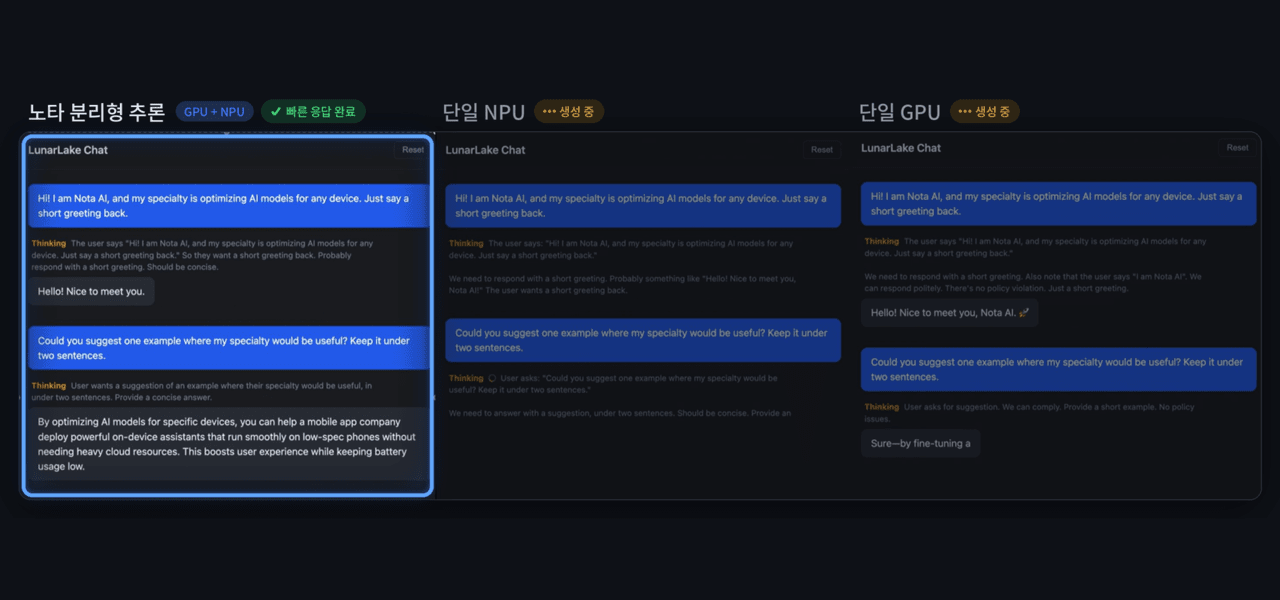
 노타의 분리형 추론(Disaggregated Inference)을 적용한 AI PC에서 동일한 LLM에 같은 입력을 준 실행 화면.
노타의 분리형 추론(Disaggregated Inference)을 적용한 AI PC에서 동일한 LLM에 같은 입력을 준 실행 화면.
[아이티비즈 김문구 기자] 노타(대표 채명수)가 AI PC 환경에서 GPU와 NPU를 함께 활용하는 이기종 컴퓨팅 기반 LLM(Large Language Model) 추론 최적화 기술을 구현했다고 4일 밝혔다.
노타는 인텔 루나 레이크(Intel Lunar Lake) 기반 AI PC에서 LLM 실행 과정을 입력 처리 단계와 답변 생성 단계로 나눠 분석하고, 각 단계에 적합한 연산 장치를 배치하는 분리형 추론(Disaggregated Inference) 방식을 적용했다. 이에 따라 입력 처리 연산은 GPU에서, 답변 생성 연산은 NPU에서 실행되도록 구성했다.
노타는 성능 평가에서 분리형 추론 방식을 적용한 결과, 단일 GPU 실행 방식 대비 토큰당 에너지 소비를 약 32% 줄이고 생성 처리량을 약 12% 높였으며, 단일 NPU 실행 방식 대비 첫 응답 지연시간을 약 89% 단축했다.
이번 성과의 핵심은 GPU와 NPU를 단순히 함께 사용한 것이 아니라, AI 모델의 작업 특성을 분석해 각 연산을 가장 적합한 장치에 배치했다는 점이다. 이는 같은 AI PC에서도 하드웨어를 어떻게 활용하느냐에 따라 실제 사용자 경험이 달라질 수 있음을 보여준다.
노타 채명수 대표는 ““노타는 모델 경량화, 런타임 최적화, 하드웨어 최적화 기술을 결합해 AI PC 시대의 온디바이스 AI 실행 효율을 높여 나가겠다”고 말했다.
![[시간들] 박정희도 못 건드린 선관위, 독립이 부른 무능의 덫](https://img0.yna.co.kr/etc/inner/KR/2026/06/09/AKR20260609092400546_01_i_P4.jpg)
![[머니톡스] 수출 초호황인데 역설적인 환율…'글로벌'의 부메랑](https://img9.yna.co.kr/etc/inner/KR/2026/06/09/AKR20260609023300546_03_i_P4.jpg)


![[이런말저런글] 들이켜다 들이키다, 들르다 들리다](https://img6.yna.co.kr/etc/inner/KR/2026/06/09/AKR20260609096200546_01_i_P4.jpg)
![[주간스타트업동향] 업스테이지, AI 에이전트 플랫폼 '타임리' 인수 外](https://it.donga.com/media/__sized__/images/2026/6/9/b157076f84f64345-thumbnail-960x540-70.jpg)

![[주간보안동향] 티빙, 이용자 개인정보 유출…침해 사고 조사 착수 外](https://it.donga.com/media/__sized__/images/2026/6/9/57875fdebf414d97-thumbnail-960x540-70.jpg)








 English (US) ·
English (US) · 