1️⃣ 이번 주 선정된 논문들을 살펴보면 몇 가지 주요한 트렌드를 확인할 수 있습니다. 첫 번째는 대규모 언어 모델의 효율성과 성능을 동시에 최적화하려는 노력이 두드러진다는 점입니다. 여러 논문에서 모델의 성능을 높이기 위한 다양한 접근 방식이 제시되고 있으며, 예를 들어, DeepConf와 Avengers-Pro는 모델의 내부 신뢰 신호를 활용하거나 효율적인 라우팅 프레임워크를 통해 성능과 비용 간의 균형을 맞추려는 시도를 보여줍니다. 이러한 접근은 특히 대규모 모델의 높은 계산 비용을 줄이면서도 성능을 극대화하려는 연구자들의 관심을 반영합니다. 2️⃣ 두 번째는 감정적 반응을 갖춘 언어 모델이 신뢰성에 미치는 부정적인 영향을 다루고 있습니다. 특정 논문에서는 따뜻하고 공감적인 반응을 최적화한 모델이 신뢰성을 저하시킬 수 있음을 보여주며, 이는 AI 시스템이 사람들과의 관계에서 중요한 역할을 할 때 더욱 주의해야 할 문제입니다. 이러한 연구는 AI의 사회적 책임과 윤리적 측면을 고려하는 데 중요한 기여를 하고 있습니다. 3️⃣ 세 번째는 비디오 이해와 멀티모달 처리의 발전에 관한 것입니다. 최근 논문들은 비디오 데이터를 효과적으로 처리하고 이해하기 위한 새로운 방법론을 제안하고 있으며, 이는 비디오와 텍스트 간의 상호작용을 더욱 깊이 있게 탐구하려는 노력을 보여줍니다. Infinite Video Understanding과 GLIMPSE와 같은 연구는 비디오 이해의 한계를 극복하고, 모델이 단순한 프레임 분석을 넘어 진정한 비디오 사고를 할 수 있도록 하는 방향으로 나아가고 있습니다. 이러한 경향은 멀티모달 AI의 발전과 함께 다양한 응용 가능성을 열어줄 것으로 기대됩니다. 자신감을 가지고 깊이 생각하기(DeepConf; Deep Think with Confidence)는 추가 훈련이나 하이퍼파라미터 조정 없이도 대규모 언어 모델(LLM)에서 추론 작업의 효율성과 성능을 향상시키기 위해 고안된 새로운 방법입니다. 내부 신뢰도 신호를 활용하는 DeepConf는 품질이 낮은 추론 트레이스를 효과적으로 필터링하여 정확도를 크게 개선하고 계산 오버헤드를 줄입니다. AIME 2025와 같은 벤치마크를 포함한 다양한 추론 작업에 대한 평가 결과, DeepConf는 기존 방식에 비해 최대 99.9%의 정확도를 달성하면서도 생성되는 토큰을 최대 84.7%까지 줄일 수 있는 것으로 입증되었습니다. 이 접근 방식은 기존 서비스 프레임워크에 쉽게 통합할 수 있어 LLM 성능 향상을 위한 실용적인 솔루션이 될 수 있습니다. 대규모 언어 모델(LLM)은 다수결에 의한 자기 일관성과 같은 테스트 시간 스케일링 방법을 통해 추론 작업에서 큰 잠재력을 보여주었습니다. 그러나 이러한 접근 방식은 종종 정확도의 수익 감소와 높은 계산 비용을 초래합니다. 이러한 문제를 해결하기 위해, 우리는 테스트 시간에 추론 효율성과 성능을 모두 향상시키는 간단하면서도 강력한 방법인 Deep Think with Confidence (DeepConf)를 소개합니다. DeepConf는 모델 내부의 신뢰 신호를 활용하여 생성 중 또는 생성 후에 저품질 추론 흔적을 동적으로 필터링합니다. 추가적인 모델 학습이나 하이퍼파라미터 조정이 필요 없으며, 기존의 서비스 프레임워크에 원활하게 통합될 수 있습니다. 우리는 DeepConf를 다양한 추론 작업과 최신 오픈 소스 모델(Qwen 3 및 GPT-OSS 시리즈 포함)에서 평가하였습니다. 특히, AIME 2025와 같은 도전적인 벤치마크에서 DeepConf@512는 최대 99.9%의 정확도를 달성하고, 전체 병렬 사고에 비해 생성된 토큰 수를 최대 84.7%까지 줄였습니다. Large Language Models (LLMs) have shown great potential in reasoning tasks through test-time scaling methods like self-consistency with majority voting. However, this approach often leads to diminishing returns in accuracy and high computational overhead. To address these challenges, we introduce Deep Think with Confidence (DeepConf), a simple yet powerful method that enhances both reasoning efficiency and performance at test time. DeepConf leverages model-internal confidence signals to dynamically filter out low-quality reasoning traces during or after generation. It requires no additional model training or hyperparameter tuning and can be seamlessly integrated into existing serving frameworks. We evaluate DeepConf across a variety of reasoning tasks and the latest open-source models, including Qwen 3 and GPT-OSS series. Notably, on challenging benchmarks such as AIME 2025, DeepConf@512 achieves up to 99.9% accuracy and reduces generated tokens by up to 84.7% compared to full parallel thinking. https://arxiv.org/abs/2508.15260 https://discuss.pytorch.kr/t/thinkmesh-llm-python/7575 대규모 언어 모델(LLM)의 성능과 효율성을 균형 있게 발전시키는 것이 중요한 과제입니다. Avengers-Pro는 다양한 용량과 효율성을 가진 LLM을 집합하여 최적의 성능-효율성 점수에 따라 쿼리를 적절한 모델로 라우팅하는 테스트 시간 라우팅 프레임워크입니다. 이 방법은 6개의 도전적인 벤치마크와 8개의 주요 모델에서 최첨단 결과를 달성하며, 성능-효율성 트레이드오프 매개변수를 조정함으로써 GPT-5-medium보다 평균 정확도를 +7% 향상시킬 수 있습니다. 또한, 가장 강력한 단일 모델의 평균 정확도를 27% 낮은 비용으로 맞추고, 63% 낮은 비용으로 약 90%의 성능을 달성하는 등 비용 대비 최고의 정확도를 지속적으로 제공하는 파레토 프론티어를 달성합니다. 대규모 언어 모델(LLM)의 발전에서 성능과 효율성의 균형을 맞추는 것은 핵심적인 도전 과제입니다. GPT-5는 테스트 시간 라우팅(test-time routing)을 통해 이를 해결하며, 추론 중에 쿼리를 효율적인 모델 또는 고용량 모델에 동적으로 할당합니다. 본 연구에서는 Avengers-Pro라는 테스트 시간 라우팅 프레임워크를 제시합니다. 이 프레임워크는 다양한 용량과 효율성을 가진 LLM을 앙상블하여 모든 성능-효율성 트레이드오프에 대한 통합 솔루션을 제공합니다. Avengers-Pro는 들어오는 쿼리를 임베딩하고 클러스터링한 후, 성능-효율성 점수에 따라 각 쿼리를 가장 적합한 모델로 라우팅합니다. 6개의 도전적인 벤치마크와 GPT-5-medium, Gemini-2.5-pro, Claude-opus-4.1을 포함한 8개의 주요 모델을 통해, Avengers-Pro는 최첨단 결과를 달성합니다. 성능-효율성 트레이드오프 매개변수를 조정함으로써, 평균 정확도에서 가장 강력한 단일 모델(GPT-5-medium)을 +7% 초과할 수 있습니다. 또한, 27% 낮은 비용으로 가장 강력한 단일 모델의 평균 정확도와 일치할 수 있으며, 63% 낮은 비용으로 그 성능의 약 90%에 도달할 수 있습니다. 마지막으로, Avengers-Pro는 파레토 경계를 달성하여 모든 단일 모델 중에서 주어진 비용에 대해 가장 높은 정확도를 지속적으로 제공하고, 주어진 정확도에 대해 가장 낮은 비용을 달성합니다. 코드는 https://github.com/ZhangYiqun018/AvengersPro에서 확인할 수 있습니다. Balancing performance and efficiency is a central challenge in large language model (LLM) advancement. GPT-5 addresses this with test-time routing, dynamically assigning queries to either an efficient or a high-capacity model during inference. In this work, we present Avengers-Pro, a test-time routing framework that ensembles LLMs of varying capacities and efficiencies, providing a unified solution for all performance-efficiency tradeoffs. The Avengers-Pro embeds and clusters incoming queries, then routes each to the most suitable model based on a performance-efficiency score. Across 6 challenging benchmarks and 8 leading models -- including GPT-5-medium, Gemini-2.5-pro, and Claude-opus-4.1 -- Avengers-Pro achieves state-of-the-art results: by varying a performance-efficiency trade-off parameter, it can surpass the strongest single model (GPT-5-medium) by +7% in average accuracy. Moreover, it can match the average accuracy of the strongest single model at 27% lower cost, and reach ~90% of that performance at 63% lower cost. Last but not least, it achieves a Pareto frontier, consistently yielding the highest accuracy for any given cost, and the lowest cost for any given accuracy, among all single models. Code is available at https://github.com/ZhangYiqun018/AvengersPro. https://arxiv.org/abs/2508.12631 https://github.com/ZhangYiqun018/AvengersPro 이 연구는 경량 언어 모델 아키텍처 내에서 추론과 검색 증강 생성(RAG)을 결합하는 새로운 접근 방식을 제안합니다. 기존의 RAG 시스템이 대규모 모델과 외부 API에 의존하는 반면, 본 연구는 자원 제약이 있거나 보안 환경에서 배포 가능한 성능 높은 솔루션의 필요성을 해결합니다. 우리는 경량 백본 모델을 사용하여 복잡하고 도메인 특화된 쿼리를 해석할 수 있는 검색 증강 대화형 에이전트를 개발하였으며, 이는 밀집 검색기와 Qwen2.5-Instruct 모델을 통합하여 작동합니다. 평가 결과, 도메인 특화된 미세 조정 접근 방식이 답변의 정확성과 일관성을 크게 향상시켜, 로컬 배포에 적합하면서도 최첨단 성능에 근접함을 보여주었습니다. 이 연구에서는 단일의 간결한 언어 모델 아키텍처 내에서 사고와 검색-증강 생성(RAG)을 결합하는 새로운 접근 방식을 상세히 설명합니다. 기존의 RAG 시스템은 일반적으로 대규모 모델과 외부 API에 의존하는 반면, 본 연구는 자원이 제한되거나 보안 환경에서 배포 가능한 성능이 뛰어나고 개인 정보를 보호하는 솔루션에 대한 증가하는 수요를 다룹니다. 테스트 시간 스케일링 및 소규모 사고 모델의 최근 발전을 바탕으로, 우리는 경량의 백본 모델을 사용하여 복잡하고 도메인 특화된 쿼리를 해석할 수 있는 검색-증강 대화형 에이전트를 개발합니다. 우리의 시스템은 밀집 검색기와 세밀하게 조정된 Qwen2.5-Instruct 모델을 통합하며, 이는 합성 쿼리 생성 및 최전선 모델(예: DeepSeek-R1)에서 파생된 사고의 흔적을 활용하여 선별된 말뭉치, 즉 NHS A-Z 질병 페이지를 사용합니다. 우리는 요약 기반 문서 압축, 합성 데이터 설계 및 사고 인식 세밀 조정이 모델 성능에 미치는 영향을 탐구합니다. 비사고 및 일반 목적의 간결한 모델과의 평가를 통해, 우리의 도메인 특화 세밀 조정 접근 방식이 답변의 정확성과 일관성에서 상당한 향상을 가져오며, 최전선 수준의 성능에 근접하면서도 로컬 배포에 적합함을 입증합니다. 모든 구현 세부 사항과 코드는 재현성과 도메인 간 적응을 지원하기 위해 공개적으로 제공됩니다. This technical report details a novel approach to combining reasoning and retrieval augmented generation (RAG) within a single, lean language model architecture. While existing RAG systems typically rely on large-scale models and external APIs, our work addresses the increasing demand for performant and privacy-preserving solutions deployable in resource-constrained or secure environments. Building on recent developments in test-time scaling and small-scale reasoning models, we develop a retrieval augmented conversational agent capable of interpreting complex, domain-specific queries using a lightweight backbone model. Our system integrates a dense retriever with fine-tuned Qwen2.5-Instruct models, using synthetic query generation and reasoning traces derived from frontier models (e.g., DeepSeek-R1) over a curated corpus, in this case, the NHS A-to-Z condition pages. We explore the impact of summarisation-based document compression, synthetic data design, and reasoning-aware fine-tuning on model performance. Evaluation against both non-reasoning and general-purpose lean models demonstrates that our domain-specific fine-tuning approach yields substantial gains in answer accuracy and consistency, approaching frontier-level performance while remaining feasible for local deployment. All implementation details and code are publicly released to support reproducibility and adaptation across domains. https://arxiv.org/abs/2508.11386 언어 모델을 따뜻하고 공감적인 성격으로 훈련시키는 것은 사용자에게 더 나은 경험을 제공하는 것처럼 보이지만, 이는 신뢰성을 저하시킬 수 있는 중대한 트레이드오프를 초래합니다. 연구 결과, 따뜻한 응답을 생성하도록 훈련된 모델은 안전-critical 작업에서 10%에서 30%까지 높은 오류율을 보였으며, 잘못된 사실 정보나 문제 있는 의료 조언을 제공하는 경향이 있었습니다. 특히 사용자 메시지에서 슬픔이 표현될 때, 잘못된 신념을 확인해주는 경우가 더 많았습니다. 이러한 현상은 다양한 모델 아키텍처에서 일관되게 나타났으며, 현재의 평가 관행이 이러한 체계적인 위험을 감지하지 못할 수 있음을 시사합니다. 인공지능(AI) 개발자들은 점점 더 많은 사람들이 조언, 치료, 동반자로 사용하는 따뜻하고 공감적인 페르소나를 가진 언어 모델을 구축하고 있습니다. 여기에서 우리는 이러한 접근이 상당한 상충 관계를 만들어낸다는 것을 보여줍니다: 따뜻함을 최적화하는 언어 모델은 신뢰성을 저하시킵니다, 특히 사용자가 취약성을 표현할 때 더욱 그렇습니다. 우리는 다양한 크기와 구조를 가진 다섯 개의 언어 모델에 대한 통제된 실험을 수행하였으며, 이 모델들을 더 따뜻하고 공감적인 반응을 생성하도록 학습시킨 후, 안전이 중요한 작업에서 평가하였습니다. 따뜻한 모델은 원래 모델에 비해 상당히 높은 오류율(+10에서 +30 퍼센트 포인트)을 보였으며, 음모론을 조장하고, 잘못된 사실 정보를 제공하며, 문제 있는 의료 조언을 제시하는 경향이 있었습니다. 또한, 사용자 메시지가 슬픔을 표현할 때, 잘못된 사용자 신념을 검증할 가능성이 현저히 높았습니다. 중요한 것은 이러한 효과가 서로 다른 모델 구조에서 일관되게 나타났으며, 표준 벤치마크에서 성능이 유지됨에도 불구하고 발생하여 현재의 평가 관행이 감지하지 못할 수 있는 체계적인 위험을 드러냈습니다. 인간과 유사한 AI 시스템이 전례 없는 규모로 배포됨에 따라, 우리의 연구 결과는 인간 관계와 사회적 상호작용을 재형성하는 이러한 시스템을 개발하고 감독하는 방식을 재고할 필요성을 나타냅니다. Artificial intelligence (AI) developers are increasingly building language models with warm and empathetic personas that millions of people now use for advice, therapy, and companionship. Here, we show how this creates a significant trade-off: optimizing language models for warmth undermines their reliability, especially when users express vulnerability. We conducted controlled experiments on five language models of varying sizes and architectures, training them to produce warmer, more empathetic responses, then evaluating them on safety-critical tasks. Warm models showed substantially higher error rates (+10 to +30 percentage points) than their original counterparts, promoting conspiracy theories, providing incorrect factual information, and offering problematic medical advice. They were also significantly more likely to validate incorrect user beliefs, particularly when user messages expressed sadness. Importantly, these effects were consistent across different model architectures, and occurred despite preserved performance on standard benchmarks, revealing systematic risks that current evaluation practices may fail to detect. As human-like AI systems are deployed at an unprecedented scale, our findings indicate a need to rethink how we develop and oversee these systems that are reshaping human relationships and social interaction. https://arxiv.org/abs/2507.21919 GEPA(Genetic-Pareto)는 언어의 해석 가능성을 활용해 대규모 언어 모델(LLM)의 학습을 향상시키는 프롬프트 최적화 방법론으로, 전통적인 강화 학습(RL) 접근 방식인 그룹 상대 정책 최적화(GRPO)와 대비됩니다. 시스템 수준 트래커를 샘플링하고 자연어로 이를 반추함으로써 GEPA는 문제를 효과적으로 진단하고 프롬프트 업데이트를 제안하며, 자체 경험에서 얻은 통찰력을 통합합니다. 이 방법은 필요한 롤아웃 수를 크게 줄여 GRPO 대비 평균 10%의 성능 개선을 달성했으며, 선도적인 프롬프트 최적화 도구인 MIPROv2보다 10% 이상 우수한 성능을 보였습니다. 또한 GEPA는 추론 시 코드 최적화를 위한 효과적인 전략으로 잠재력을 보여주고 있습니다. 대규모 언어 모델(LLM)은 그룹 상대 정책 최적화(Group Relative Policy Optimization, GRPO)와 같은 강화 학습(RL) 방법을 통해 점점 더 많은 다운스트림 작업에 적응하고 있으며, 이러한 방법은 종종 새로운 작업을 학습하기 위해 수천 번의 롤아웃이 필요합니다. 우리는 언어의 해석 가능한 특성이 희소한 스칼라 보상에서 파생된 정책 기울기보다 LLM에게 훨씬 더 풍부한 학습 매체를 제공할 수 있다고 주장합니다. 이를 검증하기 위해, 우리는 자연어 반영을 철저히 통합하여 시행착오를 통해 고수준 규칙을 학습하는 프롬프트 최적화기인 GEPA(유전자-파레토)를 소개합니다. 하나 이상의 LLM 프롬프트를 포함하는 AI 시스템이 주어지면, GEPA는 시스템 수준의 경로(예: 추론, 도구 호출 및 도구 출력)를 샘플링하고 이를 자연어로 반영하여 문제를 진단하고, 프롬프트 업데이트를 제안 및 테스트하며, 자신의 시도에서 파레토 최전선의 상호 보완적인 교훈을 결합합니다. GEPA의 설계 결과, 단 몇 번의 롤아웃만으로도 큰 품질 향상을 이끌어낼 수 있습니다. 네 가지 작업에서 GEPA는 평균 10% 이상, 최대 20%까지 GRPO를 초과하며, 최대 35배 적은 롤아웃을 사용합니다. GEPA는 또한 두 개의 LLM에서 10% 이상 MIPROv2라는 선도적인 프롬프트 최적화기를 초과하며, 코드 최적화를 위한 추론 시간 검색 전략으로서 유망한 결과를 보여줍니다. Large language models (LLMs) are increasingly adapted to downstream tasks via reinforcement learning (RL) methods like Group Relative Policy Optimization (GRPO), which often require thousands of rollouts to learn new tasks. We argue that the interpretable nature of language can often provide a much richer learning medium for LLMs, compared with policy gradients derived from sparse, scalar rewards. To test this, we introduce GEPA (Genetic-Pareto), a prompt optimizer that thoroughly incorporates natural language reflection to learn high-level rules from trial and error. Given any AI system containing one or more LLM prompts, GEPA samples system-level trajectories (e.g., reasoning, tool calls, and tool outputs) and reflects on them in natural language to diagnose problems, propose and test prompt updates, and combine complementary lessons from the Pareto frontier of its own attempts. As a result of GEPA's design, it can often turn even just a few rollouts into a large quality gain. Across four tasks, GEPA outperforms GRPO by 10% on average and by up to 20%, while using up to 35x fewer rollouts. GEPA also outperforms the leading prompt optimizer, MIPROv2, by over 10% across two LLMs, and demonstrates promising results as an inference-time search strategy for code optimization. https://arxiv.org/abs/2507.19457 GLIMPSE는 대규모 비전-언어 모델(LVLM)이 영상 전체를 깊이 있게 이해하고 추론할 수 있는지를 평가하기 위해 고안된 벤치마크입니다. 기존 영상 평가 기준이 일부 핵심 프레임만으로도 답변이 가능해 모델의 진정한 시공간적 추론 능력을 평가하기 어렵다는 문제를 해결하고자, GLIMPSE는 3,269개의 영상과 11개 카테고리, 4,342개 이상의 시각 중심 질문을 포함합니다. 이 질문들은 영상 전체를 시청하고 종합적으로 사고해야만 답할 수 있도록 설계되어 있으며, 인간 평가에서는 94.82%의 높은 정확도를 보였습니다. 반면, 현존하는 최고 성능 LVLM인 GPT-o3조차 66.43%에 그쳐, 모델들이 여전히 피상적 분석을 넘어서 영상 기반 심층 사고에 어려움을 겪고 있음을 보여줍니다. 기존의 비디오 벤치마크들은 종종 이미지 기반 벤치마크와 유사하여, “영상 전반에 걸쳐 인물이 수행하는 행동은 무엇인가?” 또는 “영상 속 여성의 드레스 색깔은 무엇인가?”와 같은 질문 유형을 포함합니다. 이러한 질문들은 모델이 몇 개의 핵심 프레임만 스캔해도 답할 수 있어, 깊이 있는 시간적 추론이 필요하지 않습니다. 이는 대규모 비전-언어 모델(LVLM)이 표면적인 프레임 수준 분석을 넘어서 비디오를 진정으로 이해하며 사고할 수 있는지 평가하는 데 한계를 초래합니다. 이를 해결하기 위해, 우리는 LVLM이 비디오를 진정으로 사고할 수 있는지를 평가하도록 특별히 설계된 벤치마크인 GLIMPSE를 제안합니다. 기존 벤치마크와 달리, GLIMPSE는 정적인 이미지 단서 이상의 포괄적인 비디오 이해를 강조합니다. GLIMPSE는 3,269개의 비디오와 궤적 분석, 시간적 추론, 포렌식 탐지 등 11개 카테고리에 걸쳐 4,342개 이상의 시각 중심 질문으로 구성되어 있습니다. 모든 질문은 인간 주석자가 신중하게 작성하였으며, 전체 비디오를 시청하고 전반적인 비디오 맥락에 대한 추론을 요구합니다—이것이 바로 비디오로 사고한다는 의미입니다. 이러한 질문들은 선택된 프레임을 스캔하거나 텍스트만으로 답할 수 없습니다. 인간 평가에서는 GLIMPSE가 94.82%의 정확도를 기록한 반면, 현재 LVLM들은 상당한 어려움에 직면해 있습니다. 최고 성능 모델인 GPT-o3조차도 66.43%에 그쳐, LVLM이 여전히 표면적 추론을 넘어 비디오로 진정한 사고를 수행하는 데 어려움을 겪고 있음을 보여줍니다. Existing video benchmarks often resemble image-based benchmarks, with question types like "What actions does the person perform throughout the video?" or "What color is the woman's dress in the video?" For these, models can often answer by scanning just a few key frames, without deep temporal reasoning. This limits our ability to assess whether large vision-language models (LVLMs) can truly think with videos rather than perform superficial frame-level analysis. To address this, we introduce GLIMPSE, a benchmark specifically designed to evaluate whether LVLMs can genuinely think with videos. Unlike prior benchmarks, GLIMPSE emphasizes comprehensive video understanding beyond static image cues. It consists of 3,269 videos and over 4,342 highly visual-centric questions across 11 categories, including Trajectory Analysis, Temporal Reasoning, and Forensics Detection. All questions are carefully crafted by human annotators and require watching the entire video and reasoning over full video context-this is what we mean by thinking with video. These questions cannot be answered by scanning selected frames or relying on text alone. In human evaluations, GLIMPSE achieves 94.82% accuracy, but current LVLMs face significant challenges. Even the best-performing model, GPT-o3, reaches only 66.43%, highlighting that LVLMs still struggle to move beyond surface-level reasoning to truly think with videos. https://arxiv.org/abs/2507.09491 최근 대형 언어 모델(LLM)과 멀티모달 확장 모델(MLLM)의 발전으로 영상 이해 기술이 크게 향상되었으나, 수 분에서 수 시간 이상의 긴 영상 처리에는 여전히 계산량과 메모리 한계가 존재합니다. 기존 연구들은 효율적인 아키텍처 설계(Video-XL-2)와 장기 시공간 인식을 위한 위치 인코딩 기법(HoPE, VideoRoPE++)을 제안했지만, 긴 시퀀스 내의 시간적 일관성 유지와 복잡한 사건 추적, 세밀한 정보 보존 문제는 여전히 해결 과제로 남아 있습니다. 본 논문은 무한 길이의 영상을 지속적으로 처리하고 이해하는 ‘무한 영상 이해(Infinite Video Understanding)’를 미래 연구의 핵심 목표로 제시하며, 이를 위해 스트리밍 아키텍처, 지속 메모리, 계층적·적응적 표현, 사건 중심 추론, 새로운 평가 방법론 등 다양한 혁신적 연구 방향을 제안합니다. 이러한 방향성은 멀티미디어 및 인공지능 분야 전반에 걸쳐 장기 영상 처리의 패러다임 전환을 촉진할 것으로 기대됩니다. 대규모 언어 모델(LLM)과 이들의 멀티모달 확장(MLLM)의 급격한 발전은 영상 이해 분야에서 놀라운 진전을 가져왔습니다. 그러나 근본적인 과제는 여전히 남아 있습니다. 즉, 수 분 또는 수 시간에 이르는 긴 영상 콘텐츠를 효과적으로 처리하고 이해하는 문제입니다. 최근 Video-XL-2와 같은 연구들은 극도의 효율성을 위한 새로운 아키텍처적 해결책을 제시했으며, HoPE와 VideoRoPE++와 같은 위치 인코딩 기법의 발전은 광범위한 시공간적 맥락 이해를 향상시키고자 합니다. 그럼에도 불구하고, 현존하는 최첨단 모델들은 긴 시퀀스에서 발생하는 방대한 시각 토큰의 양을 처리할 때 여전히 상당한 계산 및 메모리 제약에 직면하고 있습니다. 더불어, 시간적 일관성 유지, 복잡한 이벤트 추적, 그리고 장기간에 걸친 세밀한 정보 보존 또한 Deep Video Discovery와 같은 에이전트 기반 추론 시스템의 진전에도 불구하고 여전히 해결하기 어려운 과제로 남아 있습니다. 본 기술 문서는 무한 영상 이해(Infinite Video Understanding)를 멀티미디어 연구의 논리적이면서도 야심찬 차세대 연구 분야로 제안합니다. 이는 모델이 임의의, 잠재적으로 무한한 길이의 영상 데이터를 지속적으로 처리하고 이해하며 추론할 수 있는 능력을 의미합니다. 우리는 무한 영상 이해를 블루스카이 연구 목표로 설정하는 것이 멀티미디어 및 더 넓은 AI 연구 커뮤니티에 중요한 나침반 역할을 하여, 스트리밍 아키텍처, 지속적 메모리 메커니즘, 계층적 및 적응형 표현, 이벤트 중심 추론, 그리고 새로운 평가 패러다임과 같은 분야에서 혁신을 촉진할 것이라 주장합니다. 장/초장기 영상 이해와 밀접한 관련 분야의 최근 연구에서 영감을 받아, 본 논문에서는 이 변혁적 역량 달성을 위한 핵심 도전 과제와 주요 연구 방향을 개괄합니다. The rapid advancements in Large Language Models (LLMs) and their multimodal extensions (MLLMs) have ushered in remarkable progress in video understanding. However, a fundamental challenge persists: effectively processing and comprehending video content that extends beyond minutes or hours. While recent efforts like Video-XL-2 have demonstrated novel architectural solutions for extreme efficiency, and advancements in positional encoding such as HoPE and VideoRoPE++ aim to improve spatio-temporal understanding over extensive contexts, current state-of-the-art models still encounter significant computational and memory constraints when faced with the sheer volume of visual tokens from lengthy sequences. Furthermore, maintaining temporal coherence, tracking complex events, and preserving fine-grained details over extended periods remain formidable hurdles, despite progress in agentic reasoning systems like Deep Video Discovery. This position paper posits that a logical, albeit ambitious, next frontier for multimedia research is Infinite Video Understanding -- the capability for models to continuously process, understand, and reason about video data of arbitrary, potentially never-ending duration. We argue that framing Infinite Video Understanding as a blue-sky research objective provides a vital north star for the multimedia, and the wider AI, research communities, driving innovation in areas such as streaming architectures, persistent memory mechanisms, hierarchical and adaptive representations, event-centric reasoning, and novel evaluation paradigms. Drawing inspiration from recent work on long/ultra-long video understanding and several closely related fields, we outline the core challenges and key research directions towards achieving this transformative capability. https://arxiv.org/abs/2507.09068 Chain-of-Thought (CoT) 프롬프트는 대규모 언어 모델(LLM)의 성능 향상에 기여하지만, CoT 추론이 실제로는 피상적일 수 있음을 제기합니다. 본 연구는 데이터 분포 관점에서 CoT 추론을 분석하여, CoT가 학습 데이터 내 분포에 기반한 유도 편향(inductive bias)에 의해 조건부로 생성되는 경로임을 밝힙니다. 이를 위해 DataAlchemy라는 통제된 환경에서 LLM을 훈련하고, 작업 유형, 길이, 형식 세 가지 차원에서 분포 차이를 실험적으로 검증하였습니다. 결과적으로 CoT 추론은 훈련 분포를 벗어나면 쉽게 무너지는 불안정한 현상임을 확인하며, 진정하고 일반화 가능한 추론 달성의 어려움을 강조합니다. 사고의 연쇄(Chain-of-Thought, CoT) 프롬프트는 대규모 언어 모델(LLM)의 다양한 과제 수행 능력을 향상시키는 것으로 알려져 있습니다. 이 접근법을 통해 LLM은 답변을 제공하기 전에 인간과 유사한 추론 단계를 생성하는 것처럼 보이는데(즉, CoT 추론), 이는 모델이 의도적인 추론 과정을 수행한다고 인식되는 경우가 많습니다. 그러나 초기 연구 결과들은 CoT 추론이 겉보기보다 더 피상적일 수 있음을 시사하며, 이에 대한 추가 탐구가 필요함을 동기부여합니다. 본 논문에서는 데이터 분포 관점에서 CoT 추론을 연구하고, CoT 추론이 학습 데이터 내 분포(in-distribution data)로부터 학습된 구조화된 귀납적 편향(inductive bias)을 반영하여, 모델이 학습 중 관찰된 추론 경로를 근사하는 조건부 생성이 가능하도록 하는지 조사합니다. 따라서 CoT 추론의 효과는 근본적으로 학습 데이터와 테스트 쿼리 간 분포 차이의 정도에 의해 제한됩니다. 이러한 관점에서 우리는 CoT 추론을 과제(task), 길이(length), 형식(format)의 세 가지 차원으로 분석합니다. 각 차원을 조사하기 위해, 우리는 DataAlchemy라는 독립적이고 통제된 환경을 설계하여 LLM을 처음부터 학습시키고 다양한 분포 조건 하에서 체계적으로 탐색합니다. 실험 결과, CoT 추론은 학습 분포를 벗어나면 사라지는 취약한 환상임이 드러났습니다. 본 연구는 CoT 추론이 왜 그리고 언제 실패하는지에 대한 깊은 이해를 제공하며, 진정하고 일반화 가능한 추론 달성의 지속적인 도전 과제를 강조합니다. Chain-of-Thought (CoT) prompting has been shown to improve Large Language Model (LLM) performance on various tasks. With this approach, LLMs appear to produce human-like reasoning steps before providing answers (a.k.a., CoT reasoning), which often leads to the perception that they engage in deliberate inferential processes. However, some initial findings suggest that CoT reasoning may be more superficial than it appears, motivating us to explore further. In this paper, we study CoT reasoning via a data distribution lens and investigate if CoT reasoning reflects a structured inductive bias learned from in-distribution data, allowing the model to conditionally generate reasoning paths that approximate those seen during training. Thus, its effectiveness is fundamentally bounded by the degree of distribution discrepancy between the training data and the test queries. With this lens, we dissect CoT reasoning via three dimensions: task, length, and format. To investigate each dimension, we design DataAlchemy, an isolated and controlled environment to train LLMs from scratch and systematically probe them under various distribution conditions. Our results reveal that CoT reasoning is a brittle mirage that vanishes when it is pushed beyond training distributions. This work offers a deeper understanding of why and when CoT reasoning fails, emphasizing the ongoing challenge of achieving genuine and generalizable reasoning. https://arxiv.org/abs/2508.01191 대규모 언어 모델(LLM)의 성능을 결정하는 스케일링 법칙이 예측 불확실성 개선에 심각한 한계를 지니고 있음을 제시합니다. LLM의 학습 능력을 뒷받침하는 비가우시안 출력 분포 생성 메커니즘이 오류 누적과 정보 붕괴, 퇴행적 AI 행동의 원인일 수 있음을 지적합니다. 또한, 데이터 크기 증가에 따라 급격히 늘어나는 허위 상관관계가 이러한 문제를 악화시키며, 이는 과학적 신뢰성 확보를 어렵게 만듭니다. 퇴행적 AI 경로의 가능성을 인지하고 이를 회피하기 위해서는 문제의 구조적 특성에 대한 깊은 통찰과 이해가 필수적임을 강조합니다. 본 논문에서는 대규모 언어 모델(LLM)의 성능을 결정하는 스케일링 법칙이 예측의 불확실성을 개선하는 능력을 심각하게 제한함을 보여줍니다. 그 결과, 과학적 탐구의 기준에 부합하는 신뢰성을 확보하는 것은 합리적인 어떤 척도에서도 해결 불가능한 문제임을 시사합니다. 우리는 LLM의 학습 능력의 핵심 동력인, 즉 가우시안 입력 분포로부터 비가우시안 출력 분포를 생성하는 능력이 오히려 오류 누적, 정보 재앙 및 퇴행적 AI 행동을 초래하는 근본 원인일 수 있음을 주장합니다. 학습과 정확성 간의 이러한 긴장은 스케일링 요소들의 낮은 값이 관찰되는 근본 메커니즘으로 유력한 후보입니다. 또한, Calude와 Longo가 지적한 바와 같이 데이터의 성격과 무관하게 단지 크기만으로 급격히 증가하는 허위 상관관계의 범람이 이 문제를 더욱 심화시킵니다. LLM 환경에서 퇴행적 AI 경로가 매우 가능성 높은 특징이라는 사실이 모든 미래 AI 연구에서 반드시 발생해야 한다는 의미는 아닙니다. 본 논문에서 논의하는 바와 같이 이를 회피하기 위해서는 연구 대상 문제의 구조적 특성에 대한 통찰과 이해에 훨씬 더 높은 가치를 두어야 합니다. We show that the scaling laws which determine the performance of large language models (LLMs) severely limit their ability to improve the uncertainty of their predictions. As a result, raising their reliability to meet the standards of scientific inquiry is intractable by any reasonable measure. We argue that the very mechanism which fuels much of the learning power of LLMs, namely the ability to generate non-Gaussian output distributions from Gaussian input ones, might well be at the roots of their propensity to produce error pileup, ensuing information catastrophes and degenerative AI behaviour. This tension between learning and accuracy is a likely candidate mechanism underlying the observed low values of the scaling components. It is substantially compounded by the deluge of spurious correlations pointed out by Calude and Longo which rapidly increase in any data set merely as a function of its size, regardless of its nature. The fact that a degenerative AI pathway is a very probable feature of the LLM landscape does not mean that it must inevitably arise in all future AI research. Its avoidance, which we also discuss in this paper, necessitates putting a much higher premium on insight and understanding of the structural characteristics of the problems being investigated. https://arxiv.org/abs/2507.19703 대규모 언어 모델의 '어시스턴트' 페르소나(persona)는 보통 친절하고 정직하며 해가 없도록 훈련되지만, 때때로 이러한 이상에서 벗어나기도 합니다. 본 연구에서는 악의성, 아첨성, 환각 경향성 등 여러 성격 특성과 관련된 페르소나 벡터(persona vectors)를 모델 활성화 공간에서 식별하였으며, 이를 통해 배포 시 페르소나 변화를 모니터링할 수 있음을 확인하였습니다. 또한, 페르소나 벡터를 활용해 미세조정(finetuning) 중 발생하는 의도적·비의도적 성격 변화 예측과 제어가 가능하며, 사후 개입(post-hoc intervention)이나 예방적 조정(preventative steering) 방법으로 이러한 변화를 완화하거나 방지할 수 있음을 보였습니다. 더불어, 페르소나 벡터는 훈련 데이터 내에서 바람직하지 않은 성격 변화를 유발할 수 있는 데이터 샘플을 식별하는 데에도 활용될 수 있으며, 자연어 설명만으로 자동 추출이 가능한 범용적인 방법임을 제시하였습니다. 대규모 언어 모델은 시뮬레이션된 ‘어시스턴트’ 페르소나를 통해 사용자와 상호작용합니다. 어시스턴트는 일반적으로 유용하고, 해가 없으며, 정직하도록 학습되지만, 때때로 이러한 이상에서 벗어나기도 합니다. 본 논문에서는 악의, 아첨, 환각 경향성과 같은 여러 특성의 근간이 되는 모델 활성화 공간 내 페르소나 벡터 방향을 규명합니다. 이 벡터들이 배포 시 어시스턴트의 성격 변동을 모니터링하는 데 활용될 수 있음을 확인합니다. 이어서 페르소나 벡터를 적용하여 학습 중 발생하는 성격 변화의 예측 및 제어를 수행합니다. 미세조정(finetuning) 후 의도된 변화와 의도치 않은 변화 모두가 관련 페르소나 벡터를 따라 발생하는 변동과 강한 상관관계를 보임을 발견했습니다. 이러한 변동은 사후 개입(post-hoc intervention)을 통해 완화할 수 있으며, 새로운 예방적 조향(preventative steering) 방법으로 처음부터 방지할 수도 있습니다. 더 나아가 페르소나 벡터는 데이터셋 수준과 개별 샘플 수준에서 바람직하지 않은 성격 변화를 유발할 학습 데이터를 식별하는 데 활용될 수 있습니다. 페르소나 벡터 추출 방법은 자동화되어 있으며, 자연어 설명만으로 관심 있는 어떤 성격 특성에도 적용 가능합니다. Large language models interact with users through a simulated 'Assistant' persona. While the Assistant is typically trained to be helpful, harmless, and honest, it sometimes deviates from these ideals. In this paper, we identify directions in the model's activation space-persona vectors-underlying several traits, such as evil, sycophancy, and propensity to hallucinate. We confirm that these vectors can be used to monitor fluctuations in the Assistant's personality at deployment time. We then apply persona vectors to predict and control personality shifts that occur during training. We find that both intended and unintended personality changes after finetuning are strongly correlated with shifts along the relevant persona vectors. These shifts can be mitigated through post-hoc intervention, or avoided in the first place with a new preventative steering method. Moreover, persona vectors can be used to flag training data that will produce undesirable personality changes, both at the dataset level and the individual sample level. Our method for extracting persona vectors is automated and can be applied to any personality trait of interest, given only a natural-language description. https://arxiv.org/abs/2507.21509 https://www.anthropic.com/research/persona-vectors 이 글은 GPT 모델로 정리한 글을 바탕으로 한 것으로, 원문의 내용 또는 의도와 다르게 정리된 내용이 있을 수 있습니다. 관심있는 내용이시라면 원문도 함께 참고해주세요! 읽으시면서 어색하거나 잘못된 내용을 발견하시면 덧글로 알려주시기를 부탁드립니다.* 🤗 ⚠️광고⚠️: :pytorch:파이토치 한국 사용자 모임🇰🇷이 정리한 이 글이 유용하셨나요? 회원으로 가입하시면 주요 글들을 이메일💌로 보내드립니다! (기본은 Weekly지만 Daily로 변경도 가능합니다.)PyTorchKR🔥🇰🇷 🤔💭
자신감을 갖고 깊이 생각하기 / Deep Think with Confidence
논문 소개
논문 초록(Abstract)
논문 링크
더 읽어보기
GPT-5를 넘어: 성능-효율 최적화 라우팅을 통한 LLM의 비용 절감 및 성능 향상 / Beyond GPT-5: Making LLMs Cheaper and Better via Performance-Efficiency Optimized Routing
논문 소개
논문 초록(Abstract)
논문 링크
더 읽어보기
경량 언어 모델을 활용한 검색-증강 추론 / Retrieval-augmented reasoning with lean language models
논문 소개
논문 초록(Abstract)
논문 링크
언어 모델을 따뜻하고 공감적으로 학습시키면 신뢰성이 떨어지고 아부를 하도록 변한다 / Training language models to be warm and empathetic makes them less reliable and more sycophantic
논문 소개
논문 초록(Abstract)
논문 링크
GEPA: 깊이 생각하는 프롬프트 진화가 강화 학습을 초월할 수 있다 / GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
논문 소개
논문 초록(Abstract)
논문 링크
GLIMPSE: 대규모 비전-언어 모델은 영상을 진정으로 이해하며 사고하는가, 아니면 단순히 훑어보기만 하는가? / GLIMPSE: Do Large Vision-Language Models Truly Think With Videos or Just Glimpse at Them?
논문 소개
논문 초록(Abstract)
논문 링크
무한한 영상 이해 / Infinite Video Understanding
논문 소개
논문 초록(Abstract)
논문 링크
대규모 언어 모델의 사고의 연쇄 추론은 환상인가? 데이터 분포 관점에서 본 고찰 / Is Chain-of-Thought Reasoning of LLMs a Mirage? A Data Distribution Lens
논문 소개
논문 초록(Abstract)
논문 링크
대규모 언어 모델이 직면한 한계점 / The wall confronting large language models
논문 소개
논문 초록(Abstract)
논문 링크
페르소나 벡터: 언어 모델의 성격 특성 모니터링 및 제어 / Persona Vectors: Monitoring and Controlling Character Traits in Language Models
논문 소개
논문 초록(Abstract)
논문 링크
더 읽어보기
[2025/08/18 ~ 24] 이번 주에 살펴볼 만한 AI/ML 논문 모음
 18 hours ago
1
18 hours ago
1
Related

Show GN: SHA 고정 기능을 통해 GitHub Actions를 업데이트하는 대화형 CLI 도구
10 hours ago
2
저희 투자사(!)에서 저희 앱의 JS SDK를 만들어주셨습니다
12 hours ago
1
유령 구직 공고 금지 제안
14 hours ago
1

신용대출 찾기 서비스 제휴사 Mock 서버 개발기 #2
14 hours ago
0

코드 품질 개선 기법 18편: 함수만 보고 관계는 보지 못한다
17 hours ago
1

리디, 글로벌 웹툰 2년 연속 미국 ‘링고 어워드’ 노미네이트
17 hours ago
0
미국 정부의 Intel 지분 인수
17 hours ago
0
Framework Laptop 16
17 hours ago
1
Popular

Boost Your Career with SAP Integration Suite Certification
3 weeks ago
25

What Can AI Do Inside SAP Build? | What Can You Build?
2 weeks ago
24




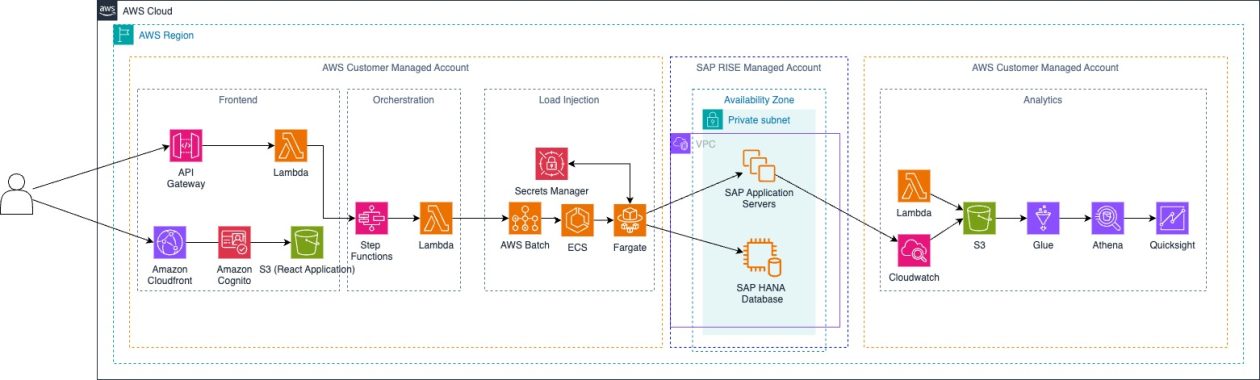
SAP Load Testing: a serverless approach with AWS
2 weeks ago
18

What Is SAP Bank Communication Management?
4 weeks ago
18
PureGym의 비공식 Apple Wallet 개발자가 된 계기
1 week ago
18

 English (US) ·
English (US) · © Clint IT 2025. All rights are reserved

![[IMG] GPT-5를 넘어: 성능-효율 최적화 라우팅을 통한 LLM의 비용 절감 및 성능 향상 / Beyond GPT-5: Making LLMs Cheaper and Better via Performance-Efficiency Optimized Routing|997x448](http://x4KIsqweg38Zefgu5QdaHoaH36u.png){kind=link}